0 前言
在上一次的介绍中,我们回顾了卷积神经网络的相关细节。本次介绍我们将回顾循环神经网络(Recurrent Neural Network)。还是让我们听听deepseek怎么评价RNN。
循环神经网络(RNN)的本质是具有内部状态记忆的序列处理器:它在每个时间步接收当前输入和前一时刻的隐藏状态,通过共享的参数矩阵进行线性变换与非线性激活,更新隐藏状态并产生输出,从而将历史信息编码进隐藏状态中,用于处理任意长度的序列数据。
1 有关RNN的基础概念
让我们先来看RNN的应用场景:传统的前馈神经网络是一个“单向”的过程,无法捕捉序列中的时序依赖关系。比如理解一句话“我吃苹果”,如果模型的参数没有记住前一个词语“我”,则模型难以准确预测后续的动词。为了解决这个问题,RNN给出的解决方案是通过循环连接将前一时刻的信息传递至当前时刻,使网络拥有“记忆”。
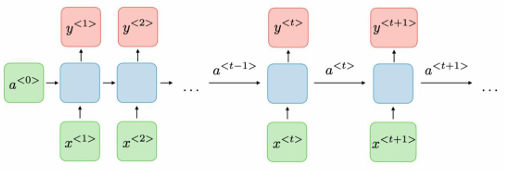
上图展示了一个最经典的RNN架构内容,对每一个时序步骤t,激活函数$a_{t}$,隐藏状态$h_t$和输出$y_{t}$,都会有下面的公式输出
\[\mathbf{h_t}=tanh(\mathbf{W}_{hh}\mathbf{h}_{t-1}+\mathbf{W}_{xh}\mathbf{x}_t+\mathbf{b}_h)\] \[\mathbf{y}_t=\mathbf{W}_{hy}+\mathbf{b}_y\]其中xh表示输出到隐藏层的权重矩阵,hh表示隐藏层到隐藏层的循环权重矩阵(核心,共享于所有时间步),hy表示隐藏层到输出层的权重矩阵,tanh为常用激活函数,将值压缩到(-1,1)之间,控制梯度范围。
从上面的介绍我们可以看到RNN在每个时间步使用同一套参数(xh,hh和hy),这使得模型能够处理变长序列,并大幅减少参数量,如果将RNN按照时间步展开,则等价于一个权值共享的深度前馈网络,深度等于序列长度。
2 RNN的训练算法
一如上面所说,RNN可以被从时间步展开。随时间反向传播(BPTT)就是基于这一思路,将展开后的RNN视为普通前馈网络,应用链式法则计算梯度。由于循环权重 $\mathbf{W}_{hh}$ 在每个时间步都参与计算,其梯度是各时间步梯度的累加:
\[\frac{\partial L}{\partial \mathbf{W}_{hh}} = \sum_{t=1}^{T} \frac{\partial L_t}{\partial \mathbf{W}_{hh}}\]而这一求导过程又依赖于从t时刻到起始时刻的连乘路径,包含多次tanh导数和$\mathbf{W}_{hh}$的乘积。因此当激活函数导数和权重连乘的模小于1时,长距离梯度指数衰减到0,导致网络无法学习长期依赖。
下面是Pytorch中使用RNN的简单示例,如果需要替换成LSTM或者GRU,只需要将nn.RNN改为nn.LSTM或者nn.GRU即可
import torch
import torch.nn as nn
# 定义模型
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# x shape: (batch, seq_len, input_size)
out, _ = self.rnn(x) # out: (batch, seq_len, hidden_size)
out = out[:, -1, :] # 取最后一个时间步的输出
out = self.fc(out)
return out
# 实例化
model = SimpleRNN(input_size=28, hidden_size=128, num_layers=2, num_classes=10)
3 RNN的主要变体
除了标准的RNN,还有很多基于RNN结构的变体。下面介绍几类常见的RNN变体
3.1 长短时记忆网络(LSTM)
长短时记忆网络(Long Short Term Memory)是RNN的一大变体,为解决传统RNN在处理长序列数据中中易出现的梯度消失/爆炸而设置。
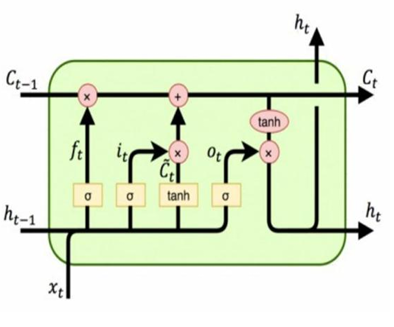
在时刻t,LSTM单元接收到当前时刻输入$x_t$,上一时刻隐藏状态$h_{t-1}$和上一时刻的细胞状态(专门用于保存长期信息)$c_{t-1}$。最后得到的输出为当前时刻隐藏状态和当前时刻细胞状态。其中细胞状态仅在 LSTM 层内部流动,不对外输出;而隐藏状态则向上层或外部输出。
LSTM包含三种门:遗忘门、输入门和输出门。每个门的输出均由当前输入$x_t$和上一隐藏状态$h_{t-1}$拼接后经过一个全连接层和sigmoid激活函数计算得出
3.1.1 遗忘门(Forget Gate)
遗忘门决定上一时刻的细胞状态$c_{t-1}$中有多少信息需要被保留,具体计算公式如下所示
\[f_t=σ(\mathbf{W}_f⋅[h_{t−1},x_t]+b_f)\]其中 σ 为 Sigmoid 激活函数,$W_f$ 和 $b_f$ 分别为权重和偏置。$f_t$ 取值在 0 到 1 之间,0 表示完全遗忘,1 表示完全保留。
3.1.2 输入门(Input Gate)
输入门决定当前输入的新信息中有多少需要写入细胞状态,分为以下两种
输入门门值(σ 为 Sigmoid 函数):
\[i_t=σ(W_i⋅[h_{t-1},x_t]+b_i)\]候选细胞状态(使用tanh激活函数)
\[\tilde{c}_t=tanh(W_c⋅[h_{t−1},x_t]+b_c)\]控制门门值$i_t$控制候选状态$\tilde{c}_t$中的信息有多少能被真正采纳
3.1.3 细胞状态更新(Cell State Update)
将遗忘门和输入门的结果结合,更新得到下面的细胞状态
\[c_t=f_t⊙c_{t−1}+i_t⊙\tilde{c}_t\]其中⊙表示逐元素相乘,线性加法结构有效缓解了梯度消失问题,门控权衡
3.1.4 输出门(Output Gate)
输出门决定当前细胞状态$c_t$中有多少信息作为隐藏状态$h_t$输出。
输出门门值为
\[o_t=σ(W_o⋅[h_{t−1},x_t]+b_o)\]隐藏状态输出为
\[h_t=o_t⊙tanh(c_t)\]细胞状态先经过 Tanh 激活函数压缩至 [-1,1],再乘以输出门门值 $o_t$,得到当前时刻的隐藏状态
下面是使用PyTorch构建LSTM模型进行时间序列预测的示例
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# LSTM 前向传播
out, _ = self.lstm(x, (h0, c0))
# 取最后一个时间步的输出
out = self.fc(out[:, -1, :])
return out
# 使用示例
model = LSTMModel(input_size=10, hidden_size=64, num_layers=2, output_size=1)
3.2 门控循环单元(Gated Recurrent Unit, GRU)
GRU由 Cho 等人在 2014 年提出,是长短期记忆网络(LSTM)的一种高效变体。它在保持对长距离依赖建模能力的同时,通过简化门控结构、合并状态向量来减少参数数量和计算开销,在许多序列建模任务中能够达到与 LSTM 相当甚至更优的性能。
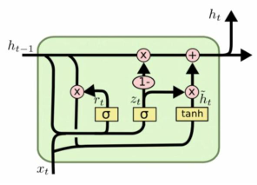
GRU的设计原则是在保留核心门控理念的前提下精简结构,只使用两个门——重置门和更新门,分别控制历史信息的丢弃程度和新旧信息的混合比例。
在时刻t,GRU单元接收当前时刻输入$x_t$和上一时刻隐藏时刻$h_{t-1}$。输出为当前时刻的隐藏状态$h_{t}$。
GRU 的两个门均由当前输入 $x_t$和上一隐藏状态$h_{t-1}$拼接后,通过一个全连接层和 Sigmoid 激活函数计算得出,值域为 ([0, 1])。
重置门决定在生成当前候选隐藏状态时,多少过去信息需要被忽略。其计算公式如下所示
\[r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r)\]当$r_t$趋近于0时,模型倾向于“忘记”历史信息,仅依赖当前输入构建候选隐藏状态,当$r_t$趋近1时,完整保留历史信息
更新门$z_t$决定历史状态在多大程度上被保留到当前状态,同时控制候选隐藏状态的注入程度。它实现了LSTM中遗忘门和输入门的双重功能:$z_t$趋近于1时,模型倾向于完全保留历史状态忽略新信息;$z_t$趋近于0时模型则更倾向于依赖当前新信息
\[z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z)\]GRU的最终隐藏状态$h_t$由更新门对历史状态和候选状态进行线性插值得到。候选隐藏状态$\tilde{h}_t$ 表示当前时刻提取出的“新信息”,其计算方式类似于传统 RNN,但受到重置门的调制。
\[\tilde{h}_t = \tanh(W_h \cdot [r_t \odot h_{t-1}, x_t] + b_h)\] \[h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t\]下面还是一个使用pytorch调用GRU模块的代码
import torch
import torch.nn as nn
# 定义参数
input_size = 10 # 输入特征维度
hidden_size = 20 # 隐藏状态维度
num_layers = 2 # 网络层数
batch_size = 4
seq_len = 5
# 创建 GRU 层
# batch_first=True 表示输入形状为 (batch, seq, feature)
gru = nn.GRU(input_size, hidden_size, num_layers,
batch_first=True, bidirectional=True)
# 构造输入 (batch_size, seq_len, input_size)
x = torch.randn(batch_size, seq_len, input_size)
# 前向传播
# output: (batch_size, seq_len, hidden_size * num_directions)
# h_n: (num_layers * num_directions, batch_size, hidden_size)
output, h_n = gru(x)
print("Output shape:", output.shape) # (4, 5, 40)
print("h_n shape:", h_n.shape) # (4, 4, 20)